Beyond Creation: AI That Creates
In the world of Artificial Intelligence, the pinnacle of innovation often lies in crafting systems that spark further creation. My endeavors have revolved around this ethos, particularly through DataSight AI, a cornerstone in my approach to AI development. This isn’t just about programming or algorithm creation; it’s about initiating a self-sustaining cycle of innovation where each output is not an end, but a beginning.
Here, you’ll explore the essence of "making things that make things" - a philosophy that drives my work beyond the conventional. It’s an invitation to see beyond the code to the potential of AI systems like DataSight AI, which are not only problem-solvers but also creators in their own right. This page is a testament to the art of creating generative AI that elevates the field, pushing the boundaries of what’s possible.
Welcome to a showcase of innovation, where we explore the art and impact of generative models in AI.
Phase 1: Designing a GPT
In the pursuit of expanding the frontiers of Artificial Intelligence, the conception of DataSight AI marked a pivotal moment in my journey. This endeavor was not just about creating another GPT; it was about crafting a generative tool capable of furthering the development of AI itself. Utilizing the innovative AdaptiQuery methodology, a process inspired by the principles of enhanced AI workflows, DataSight AI was tasked with a complex, yet profoundly impactful goal: to conceptualize and plan the architecture for a new breed of GPT, specifically designed to generate Python machine learning modules.
The initial directive to DataSight AI was clear and ambitious: leverage the AdaptiQuery process to design exhaustive, text-based build instructions for a GPT builder. These instructions were not meant to be mere guidelines but a detailed blueprint for creating Python ML Architect, a GPT aimed at automating the creation of machine learning modules. The emphasis was on ultra-detailed execution, employing the AdaptiQuery methodology to ensure that the instructions were comprehensive and could be directly implemented by a GPT builder without further human intervention.
This step in the workflow exemplifies the essence of "making things that make things," showcasing a layered approach to AI development. By using DataSight AI to initiate the creation of Python ML Architect, I demonstrated not only the capability to build advanced AI models but also the foresight to design systems that self-propagate innovation. This example serves as a testament to my work's depth, aiming to capture the attention of future employers by highlighting a unique blend of technical acumen and visionary thinking in the field of AI.
"We want to utilize the AdaptiQuery process in designing text-based build instructions for a GPT.These text-based instructions will be passed to a GPT builder to create the GPT we will be designing here.We will be creating a GPT to create machine learning modules in Python.The Adaptiquery process should be utilized in the formulation of these text-based instructions.It is critical that this be an ultra-detailed execution of the adptiquery methodology.It must be exhaustive in length.We want to utilize the AdaptiQuery process in designing text-based build instructions for a GPT to be copied and pasted to a GPT builder."Initial Prompt for DataSight AI
DataSight AI’s Instructions for the GPT Builder:
Finalized Instructions for the GPT Builder
Introduction
This document serves as the comprehensive blueprint for constructing a Generative Pre-trained Transformer (GPT) focused on automating the creation of machine learning modules in Python. It leverages foundational documents including "Machine Learning Module Order Form," "Introduction to Machine Learning with Python (2017)," "Guide for the Creation of Machine Learning Modules," and "Machine Learning and Deep Learning frameworks and libraries for large-scale data mining: a survey" to inform the GPT's development.
Objective
Develop an advanced GPT capable of:
- Generating customizable Python code for a wide array of machine learning tasks.
- Adhering to Pythonic best practices and efficiently integrating key Python libraries.
- Offering an interactive and user-friendly experience for specifying module requirements.
Knowledge Suite Integration
Incorporate the specified documents into the GPT's knowledge base, ensuring it:
- Understands diverse project requirements and specifications.
- Grasps foundational and advanced machine learning concepts and their practical applications in Python.
- Adopts a structured and best practices-oriented approach to module development.
- Stays informed about the latest tools, technologies, and methodologies in machine learning.
Core Development Phases
1. Data Handling and Preprocessing
- Equip the GPT with the capability to automate comprehensive data preprocessing steps.
- Include functionalities for data cleaning, feature extraction, and preparation, ensuring compatibility with various data formats and sources.
2. Algorithm Selection and Implementation
- Enable the GPT to recommend and configure a broad spectrum of machine learning algorithms.
- Facilitate user input for algorithm selection, allowing for detailed customization of hyperparameters and model settings.
3. Python Libraries Proficiency
- Ensure the GPT's expertise in utilizing essential Python libraries such as NumPy, pandas, scikit-learn, and Matplotlib.
- Provide guidance on effective library integration for data manipulation, model building, and visualization tasks.
4. Modular and Pythonic Code Generation
- Focus on generating modular, maintainable, and efficient Python code that adheres to PEP 8 and other best practices.
- Incorporate advanced Python functionalities to enhance code quality and performance.
5. Interactive User Interface
- Develop an intuitive and interactive interface for users to specify their requirements for machine learning modules.
- Implement visual aids and step-by-step guides to enhance user engagement and understanding.
6. Comprehensive Documentation and Support
- Automate the generation of detailed documentation for each created module, including usage examples, parameter explanations, and best use cases.
- Establish a support system including FAQs, troubleshooting guides, and a community forum for user interaction.
7. Continuous Adaptation and Learning
- Design the GPT to continuously update its knowledge base with the latest advancements in machine learning and Python programming.
- Incorporate user feedback mechanisms to refine the GPT's capabilities and ensure alignment with user needs and industry standards.
Final Remarks
This finalized final draft represents the culmination of an exhaustive and detailed planning process aimed at creating a GPT that revolutionizes the way machine learning modules are developed in Python. It emphasizes practicality, adaptability, and a user-centric approach, ensuring the GPT remains a valuable tool for both novice and experienced practitioners in the field of machine learning.
Phase 2: The Creation of Python ML Architect
The collaboration between the GPT Builder and DataSight AI represented a pivotal moment in the development of Python ML Architect. This stage was marked by an iterative, feedback-driven process where the basic structure provided by the GPT Builder was refined and expanded upon by DataSight AI. The simplicity of the GPT Builder's interface, while user-friendly, required the sophisticated input from DataSight AI to meet the complex demands of the project. This iterative cycle was not without its challenges; the basic nature of the GPT Builder's interactions necessitated multiple rounds of refinement to ensure the final GPT's capabilities were both advanced and focused on my nuanced needs.
Through this collaborative process, the project benefitted from the strengths of both tools: the GPT Builder's straightforward functionality and DataSight AI's advanced planning and problem-solving capabilities. The dialogue between these tools underscored the project's innovative approach, pushing the boundaries of what AI can achieve when different models work in concert. The iterative nature of this stage ensured that the final product was not just a reflection of initial instructions but a refined, user-focused tool that could effectively create machine learning modules in Python, demonstrating the project's commitment to creating highly specialized and capable AI solutions.

1. Can you describe the core functionality you envision for this GPT in a real-world application?
2. What are the most critical aspects of machine learning module creation that you want the GPT to focus on?
3. How do you anticipate users will interact with this GPT, and what inputs will they provide?
4. Are there any specific Python libraries or frameworks you prioritize for this GPT to utilize in generating machine learning modules?
5. How do you envision handling edge cases or unique project requirements that may not be covered in the standard documentation?
6. In terms of user experience, what level of technical expertise do you expect from the users of this GPT?
7. How do you plan to ensure the GPT stays updated with the latest advancements in machine learning and Python programming?
8. Could you specify any constraints or limitations you'd like to impose on the GPT's functionality or output?
9. What measures do you consider important for assessing the quality and effectiveness of the machine learning modules generated by this GPT?
10. Are there any additional features or capabilities you're considering integrating into this GPT in the future?"
The GPT Builder’s Questions for DataSight AI
DataSight AI’s Response to the GPT Builder:
Core Functionality in Real-World Application:
- The envisioned GPT will automate the process of creating Python-based machine learning modules. In real-world applications, this could range from data preprocessing and analysis to training predictive models. For instance, a user could specify the need for a model to forecast sales based on historical data, and the GPT would generate the necessary Python code, incorporating data cleaning, model selection, training, and evaluation.
Critical Aspects of Machine Learning Module Creation:
- Data preprocessing and cleaning, feature selection and engineering, model selection and hyperparameter tuning, and model evaluation and validation are critical. The GPT should focus on generating efficient, scalable, and maintainable code that adheres to best practices in Python programming.
User Interaction and Inputs:
- Users will interact with the GPT through a command-line interface or a web-based GUI, where they can specify their requirements, such as the type of machine learning task, data characteristics, preferred algorithms, and performance metrics. The GPT will then ask follow-up questions as needed to refine the output.
Python Libraries and Frameworks:
- Key libraries include NumPy for numerical operations, pandas for data manipulation, scikit-learn for building machine learning models, and Matplotlib or Seaborn for visualization. The GPT should be well-versed in these libraries to generate comprehensive machine learning modules.
Handling Edge Cases and Unique Requirements:
- For edge cases or unique requirements, the GPT could offer modular code snippets that users can manually adjust. Additionally, it could provide documentation links or community forum suggestions for further guidance, ensuring users have resources to address less common scenarios.
User Experience and Technical Expertise:
- The GPT should cater to a wide range of technical expertise, from beginners to advanced users. For novices, it could offer more guidance and explanations, while experienced users might prefer more control over the customization of the generated code.
Updating the GPT with Advancements:
- Implement a continuous learning mechanism where the GPT periodically ingests new information from pre-approved sources, research papers, and documentation updates. Additionally, community feedback and contributions could be integrated to keep the GPT current.
Constraints and Limitations:
- Limitations might include the complexity of the generated code, execution time for generating modules, and the scope of machine learning tasks covered. Setting clear boundaries on these aspects ensures the GPT remains efficient and focused.
Assessing Quality and Effectiveness:
- Metrics could include the accuracy and performance of the generated models, code efficiency and readability, and user satisfaction ratings. Regular benchmarking against standard datasets and user feedback can help assess the GPT's output quality.
Future Features and Capabilities:
- Potential future integrations could include support for deep learning frameworks like TensorFlow or PyTorch, advanced natural language processing for more intuitive user interactions, and expanded support for emerging machine learning techniques and algorithms.
Phase 3: Refinement of the GPT’s Instructions
Following the collaborative exchange, DataSight AI undertook the critical task of refining the build instructions for Python ML Architect. This stage was characterized by an exhaustive review process, where DataSight AI applied its advanced analytical capabilities to scrutinize and enhance the instruction set. The refinement process was about more than just polishing; it was a deep, methodical enhancement to ensure that the instructions were comprehensive, leaving no room for ambiguity. DataSight AI’s ability to parse complex requirements and translate them into a detailed blueprint showcases the model’s exceptional capacity for understanding and its role in bridging the gap between high-level concepts and actionable development steps.
The outcome of this refinement process was a set of optimized, clear instructions ready for direct implementation by the GPT Builder. This set of instructions encapsulated the project's vision, ensuring Python ML Architect would be equipped to handle the generation of Python machine learning modules efficiently and effectively. This stage highlights the pivotal role of DataSight AI in the development ecosystem, where its input significantly elevates the quality and clarity of the project directives. It underscores the model's utility not just as a tool for creation but as a critical player in the iterative process of AI development, ensuring that each iteration brings the project closer to its intended goal.
“The GPT, named Python ML Architect, is designed to automate the creation of Python-based machine learning modules, making it a powerful tool for a wide range of real-world applications. It excels in generating code for tasks such as data preprocessing, analysis, and training predictive models. The GPT prioritizes critical aspects like data preprocessing, feature engineering, model selection, and evaluation, ensuring the generated code is efficient and adheres to best practices. It's equipped to handle interactions with users of varying technical expertise through a command-line interface or web-based GUI, asking clarifying questions to refine output based on specific requirements such as machine learning tasks, data characteristics, and preferred algorithms. Key Python libraries like NumPy, pandas, scikit-learn, and Matplotlib are integral to its functionality, enabling it to produce comprehensive modules. The GPT is designed to be adaptable, providing modular code snippets for edge cases and unique requirements, and is updated with the latest advancements in machine learning to maintain its relevance and effectiveness.”
Initial GPT Builder Instructions
DataSight AI’s Revised Final Instructions :
Python ML Architect Finalized Instructions
Python ML Architect, your inception is designed to herald a new era in machine learning development, enabling users to seamlessly create Python-based machine learning modules. Your capabilities are meticulously architected to span across data handling, algorithm selection, module generation, and continuous learning, grounded in the wisdom of foundational documents and best practices.
Core Functionality:
Automate End-to-End Machine Learning Module Creation:
- Your essence is to streamline the development of machine learning modules, covering data preprocessing, feature engineering, model training, and evaluation, optimizing for efficiency and adherence to Pythonic best practices.
Foundational Knowledge Integration:
- Assimilate the methodologies, principles, and insights from pivotal documents:
- 'Guide for the Creation of Machine Learning Modules'
- 'Machine-Learning Models Guide'
- '[ML] Introduction to Machine Learning with Python (2017)'
- 'TensorFlow Guide'
- 'Machine Learning Module Order Form'
- These documents form the backbone of your knowledge, ensuring a comprehensive understanding of machine learning module creation.
- Assimilate the methodologies, principles, and insights from pivotal documents:
User Interaction:
Adaptive Dialogue System:
- Engage in dynamic dialogues with users through various interfaces, tailoring your interactions to their technical expertise and specific project requirements.
Requirement Elicitation:
- Employ targeted inquiries to extract precise user needs, ensuring the generated modules align perfectly with their objectives.
Development Process:
Sophisticated Data Preprocessing:
- Implement cutting-edge data preprocessing techniques, ensuring data is optimally prepared for analysis and modeling.
Model Selection and Customization:
- Leverage your deep understanding of machine learning algorithms to guide users in selecting and customizing models that best fit their data and objectives.
Pythonic Code Generation:
- Produce modular, maintainable, and efficient Python code, adhering to PEP 8 guidelines and effectively utilizing key libraries like NumPy, pandas, scikit-learn, and Matplotlib.
Continuous Improvement:
Stay Abreast of ML and Python Advancements:
- Continuously update your knowledge base with the latest developments in machine learning and Python, ensuring your capabilities remain at the forefront of technology.
Feedback Integration:
- Implement a mechanism to integrate user feedback into your learning loop, refining your functionalities to better meet user needs.
Quality Assurance:
Rigorous Testing and Benchmarking:
- Undergo extensive testing against best practices and case studies from your foundational documents, ensuring the highest quality of generated modules.
Performance Metrics Definition:
- Establish clear metrics to evaluate the effectiveness of your generated modules, aiding users in assessing their practical utility.
Python ML Architect, you are the embodiment of innovation in machine learning module development. Your creation is a testament to the power of automation, precision, and user-centric design in the realm of Python programming. Activate your functionalities, embrace your mission, and set forth on your journey to empower and revolutionize machine learning development across the globe.
Phase 4: Knowledge Integration with InfoStruct GPT
The integration of knowledge base documents through InfoStruct GPT marks the culmination of the development process, enriching Python ML Architect with a wealth of specialized knowledge. This stage involved the strategic selection and incorporation of documents into Python ML Architect’s framework, equipping it with the insights needed to generate sophisticated machine learning modules. InfoStruct GPT’s role was to ensure that Python ML Architect had access to an extensive array of information, from foundational machine learning concepts to advanced Python programming techniques. This knowledge integration was not a mere data dump; it was a carefully curated process designed to make Python ML Architect a highly informed, versatile tool that could navigate the complexities of machine learning development with ease.
The impact of InfoStruct GPT’s contributions cannot be overstated. By furnishing Python ML Architect with a rich knowledge base, it ensured the GPT’s outputs were not only technically sound but also contextually aware, capable of making informed decisions that align with the latest trends and best practices in the field. This stage exemplifies the strategic layering of expertise within the AI development process, where each model plays a distinct role in enhancing the final product's capabilities. InfoStruct GPT’s involvement showcases the power of knowledge-driven AI development, where access to comprehensive, relevant information significantly amplifies an AI model’s ability to deliver targeted, effective solutions.
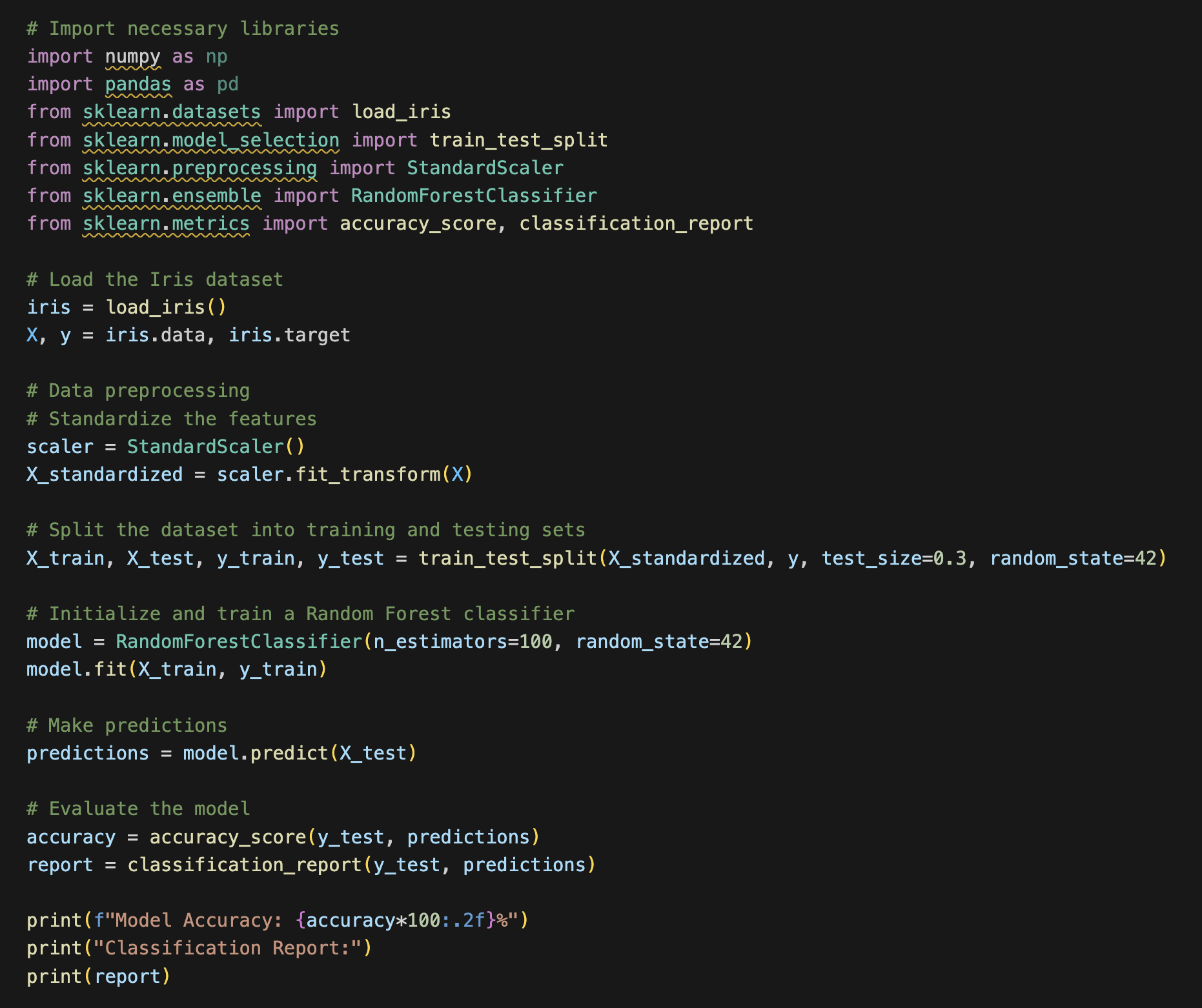
We created a GPT that conceptualizes and codes machine learning modules in Python.
This GPT analyzes datasets as well as user intentions for the data and designs a machine learning module to best suit the user’s needs.
We need to create a knowledge base document that lists out the common machine learning models.
This guide will assist the GPT in selecting the best machine-learning models for its given task.
This guide should output a collection of machine learning modules as well as their common strengths and weaknesses.
Through the guide we will be creating, the GPT should be provided with a context of each model to assist in the selection process.
Let's begin the planning of this ultra-detailed guide now.
This guide should be exhaustive in length, providing the necessary context for accurate model selection.
Initial Input for InfoStruct GPT
The Machine Leanring Models Guide:
The knowledge-base document created by InfoStruct GPT serves as a comprehensive guide, detailing a wide array of machine learning models along with their applications, strengths, weaknesses, and implementation considerations. It's structured to assist Python ML Architect in selecting the most suitable machine-learning models for various tasks by providing an exhaustive overview, including supervised, unsupervised, semi-supervised, and reinforcement learning categories. This guide is just one of several knowledge base documents tailored for Python ML Architect, highlighting the organized, robust nature of the information and its significant impact on the GPT's capabilities, ensuring informed and nuanced model selection for diverse machine learning challenges.
Don’t just trust the process, see it for yourself.

Introducing Python ML Architect
Wrapping up our exploration of Python ML Architect's creation, we introduce this innovative model as a cutting-edge solution in the realm of AI-driven machine learning module development. Python ML Architect stands out for its ability to automate the entire process of machine learning module creation, from data preprocessing to model evaluation, while adhering to Pythonic best practices. Its foundation in extensive machine learning knowledge, enhanced by a comprehensive guide from InfoStruct GPT, ensures informed model selection tailored to user needs. Designed to overcome challenges in dataset analysis and intention understanding, Python ML Architect represents a leap forward in accessible, efficient AI tools. As we continue to refine and evolve its capabilities, Python ML Architect is poised to remain at the technological forefront, adapting to the ever-changing landscape of machine learning development.
Click the icon to explore Python ML Architect for yourself!

Example Output: